Systematic Biology | 沈星星课题组提出构建最大似然树的最优策略
2024年6月28日,浙江大学沈星星课题组在《系统生物学》(Systematic Biology)期刊发表了题为“The influence of the number of tree searches on maximum likelihood inference in phylogenomics”的研究论文。该研究提出:通过调整系统发育基因组分析中的起始树以及搜索次数,可以找到推断最大似然树的最优解决方案。

重建物种或序列间的演化关系对于理解遗传和表型多样性的演化模式至关重要。最大似然法(Maximum Likelihood,简称ML)是分子系统发育学中使用最为广泛的方法之一。由于最大似然法搜索空间巨大(例如,10个物种或者10条基因序列存在2.027 x 10^6 棵候选树),现有计算资源并不能对每一个候选树进行一一检索并评估。因此,在现有ML软件中,似然树搜索是一个迭代过程,类似一个攀登高峰的过程。它始于一棵起始树(如邻接树:BioNJ tree、随机树:Random tree、或简约树:Parsimony tree),通过改变起始树的树形并计算其似然值,然后判断树形的改变是否带来似然值的增加。当迭代至无法找到更高似然值的树时,最终得到的演化树便视为最优似然树(即最大似然树,ML tree)(图1)。为了尽可能地找到最大似然树,研究者通常采取从不同起始树开始的独立搜索。类似从不同的山脚下出发并爬山,最后根据所有观察的高峰取最高峰值。然而,什么样的起始树较好,以及该进行多少次似然树搜索依然研究很少。
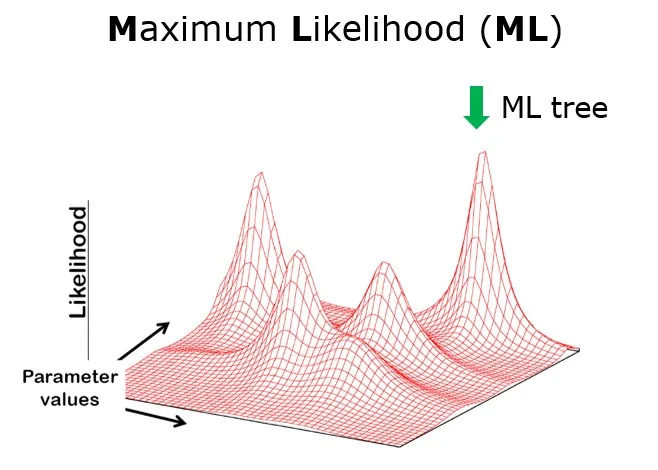
图1 基于似然法搜索最优演化树的简化图
不同起始树是否影响ML树推断?
当分别从三种起始树(BioNJ tree, Parsimony tree, 以及Random tree)开始,对给定的 ML软件(IQ-TREE, RAxML-NG, 以及 PhyML)执行一次独立的树搜索时,我们的研究结果表明:随机起始树(Random tree)在找到最佳ML基因树效率较低,运行时间较长。另外,BioNJ起始树略优于Parsimony起始树。因此,我们建议在当前基于ML搜索软件应该优先考虑BioNJ树作为起始树(图2)。
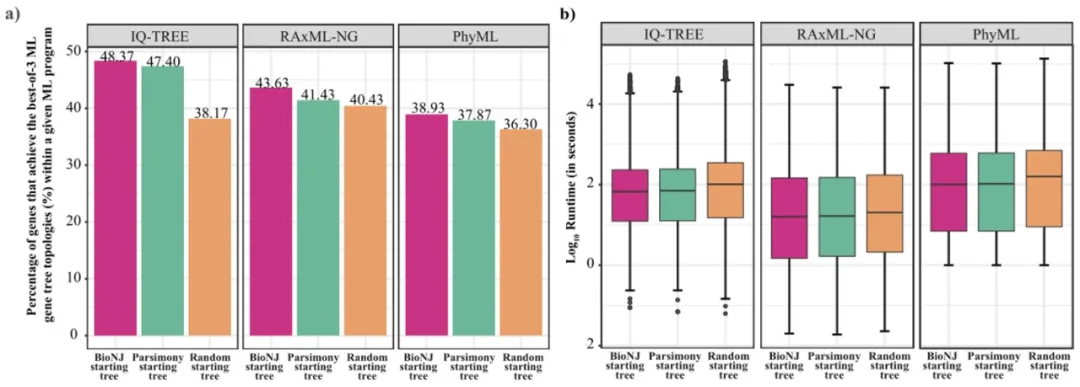
图2 不同起始树对ML基因树推断的影响
不同搜索次数是否影响ML树推断?
研究发现,约69%的单基因树在10次树搜索后达到最高似然分数(100次搜索中的最高值),这在大多数系统发育基因组研究中是可行的。然而,对于包含超过100个物种的四个动物数据集(蜜蜂、鸟类、蝴蝶和海洋鱼类)、一个植物数据集(绿色植物)和一个真菌数据集(出芽酵母),使用10次树搜索很难达到最高似然分数(图3)。
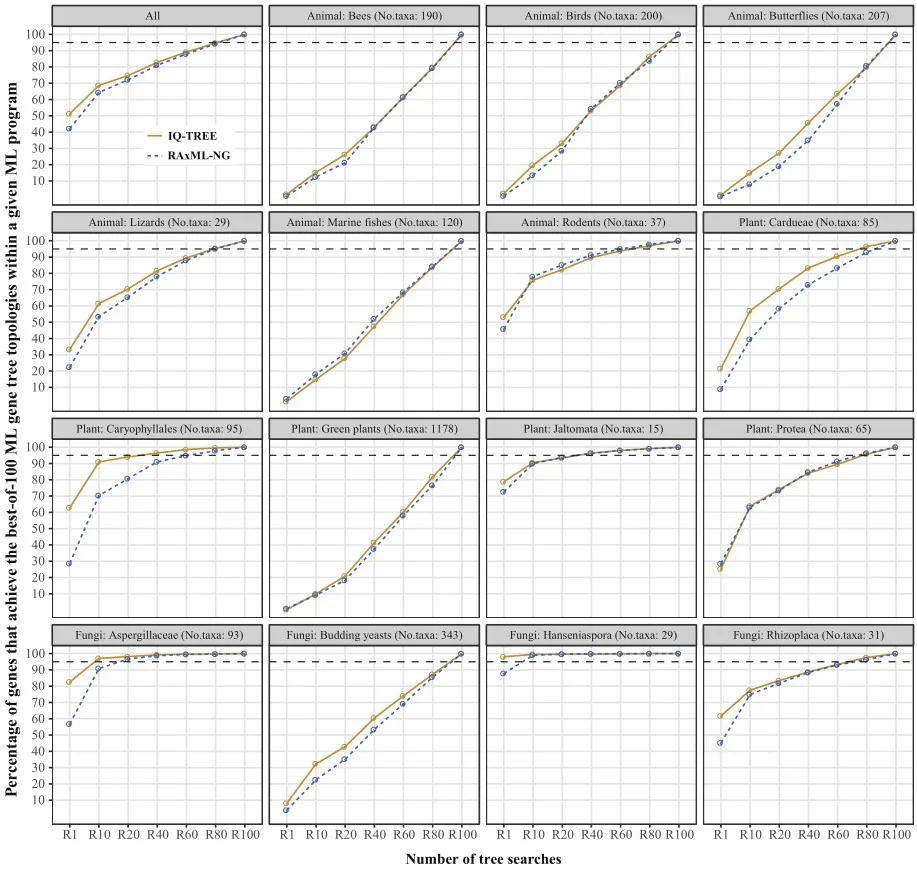
图3 不同搜索次数对ML基因树影响
由于单基因树常用于溯祖树的推断(ASTRAL方法),我们评估了树搜索次数对ASTRAL推断的影响。我们发现:1、10、20、40、60、80、100次树搜索推断的最佳单基因ML树对ASTRAL溯祖树具有显著影响。我们的结果表明,基于ASTRAL方法的溯祖树应考虑树搜索次数对单基因ML树推断的影响。具体来说,进行更多树搜索次数有利于ASTRAL物种树的节点支持率和分枝长度准确性的估算。具体需要多少次,取决于计算资源的多少。我们建议至少20次单基因ML搜索,然后再构建ASTRAL溯祖树。此外,对于串联法推断物种树,使用10次树搜索足以生成稳健的ML树(图4)。
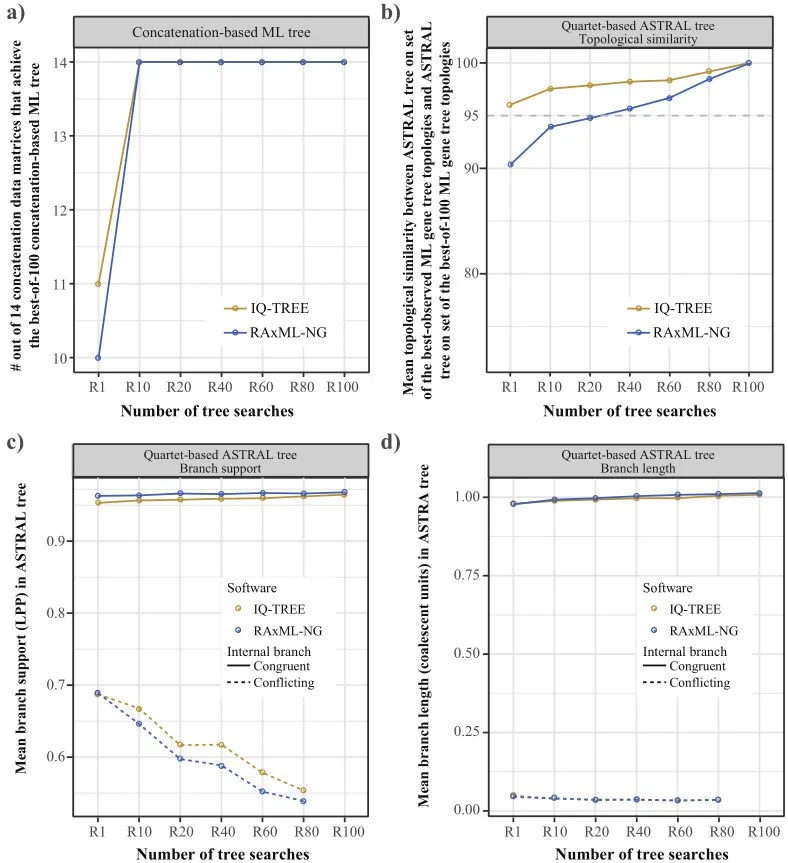
图4 不同搜索次数对串联和溯祖树推断的影响
进行大量树搜索是否必要?
我们的结果表明(图5),增加树搜索次数可以提高似然分数,但超过10次树搜索的边际回报在15个数据集中差异很大。此外,对真实数据集和模拟数据集的分析都显示,序列比对的难度系数(Difficulty score)与找到最佳ML基因树拓扑结构的机会最相关。基于模拟数据集的结果表明:对于容易分析的序列比对(难度分数≤0.3),增加树搜索次数有利于ML系统发育推断的似然值优化和拓扑准确性。相反,对于中等(难度分数0.3-0.7)和困难的序列比对(难度分数>0.7),大量树搜索可能是不必要的或有负面影响的。比对序列的难易程度值可采用最新RAxML课题组Pythia进行计算。
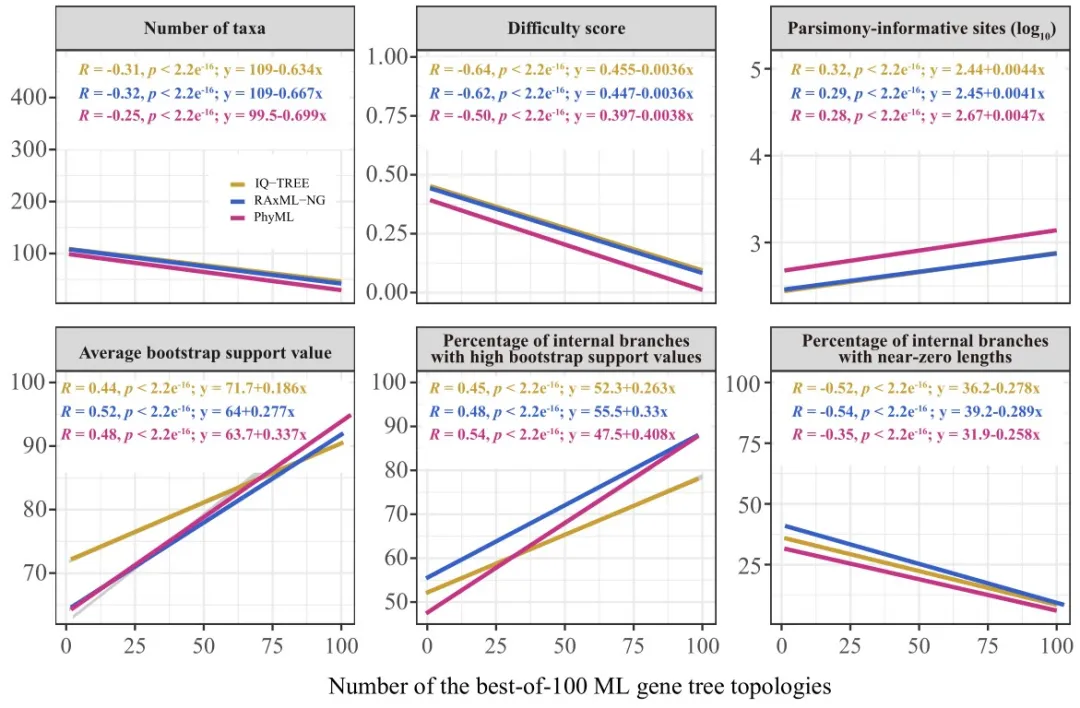
图5 最佳ML基因树与不同参数特征之间的相关性
总结
我们的研究探讨了起始树类型和不同搜索次数对ML树构建的影响。我们发现:1)BioNJ树应该优先被考虑为起始树;2)数据难度分数可以作为一个有用的预测指标,用于估计必要的树搜索次数。如果计算资源允许,建议对IQ-TREE进行至少20次树搜索,对RAxML-NG和PhyML进行至少10次树搜索;3)现有主流ML软件在树搜索过程存在显著不同,因此直接比较不同软件树搜索策略优劣是不合理的。如果非要直接比较,请限定每个软件运行时间和计算资源一模一样,然后进行比较相应输出似然树。
该研究受到了“十四五”国家重点研发计划青年科学家、浙江省自然基金杰出青年项目、国家自然科学基金等项目支持。
原文链接:
https://doi.org/10.1093/sysbio/syae031
点击文末 阅读原文,查看文章链接。








